

人工智能的零數(shù)據(jù)、小數(shù)據(jù)、大數(shù)據(jù)和全數(shù)據(jù)方法
責編:gltian |2024-07-30 16:53:352024年6月召開的中國科學院院士大會上,我應邀作了一個以“數(shù)學與人工智能”為題的大會報告。會后許多院士都希望我把報告的主要內(nèi)容寫出來,這是這篇短文的由來。在這篇文章中,我試圖用相對通俗但又不掩蓋核心問題的語言解釋人工智能的一些主要方法和它們各自的特點。
人工智能的眾多不同方法,可以根據(jù)其所用數(shù)據(jù)量的大小,分為零數(shù)據(jù)、小數(shù)據(jù)、大數(shù)據(jù)和全數(shù)據(jù)方法。當然,數(shù)據(jù)不是人工智能發(fā)展的唯一線索,但它可以比較方便地幫助我們梳理人工智能發(fā)展過程中出現(xiàn)的不同想法。
零數(shù)據(jù)
邏輯推理、符號計算、專家系統(tǒng)等原則上都不需要數(shù)據(jù)。邏輯推理方法的主要思路是構造算法和軟件模仿人的推理過程。符號表示和符號計算試圖把邏輯推理更加形式化、自動化。在1956年的達特茅斯(Dartmouth)會議上,紐厄爾(Newell)、肖(Shaw)和西蒙(Simon)推出的邏輯理論(Logic Theorist)系統(tǒng)就是一個這樣的例子。邏輯理論被認為是第一個人工智能系統(tǒng),它能夠證明許多數(shù)學定理,還能下棋。
專家系統(tǒng)的目標是把專家知識用軟件系統(tǒng)實現(xiàn)運用。專家系統(tǒng)最成功的例子是IBM的深藍(Deep Blue),它在1997年戰(zhàn)勝了國際象棋冠軍卡斯帕羅夫(Kasparov)。其他零數(shù)據(jù)方法方面典型的工作包括LISP語言和數(shù)學定理機器證明的“吳方法”。
小數(shù)據(jù)
線性回歸、邏輯回歸、支持向量機等統(tǒng)計學習方法是典型的小數(shù)據(jù)方法。早期的神經(jīng)網(wǎng)絡,如感知機(perceptron),也是小數(shù)據(jù)方法。隱式馬爾可夫過程(HMM)、N-gram、深度學習出現(xiàn)之前的機器學習方法等,也都是小數(shù)據(jù)方法。過去的模式識別、自然語言處理、語音技術、機器人技術等都是基于小數(shù)據(jù)(或零數(shù)據(jù))方法實現(xiàn)的。很長一段時間里,人工智能是靠這類方法支撐的。
零數(shù)據(jù)和小數(shù)據(jù)方法往往對簡單問題(如跳棋、象棋等)比較有效,但是在復雜問題面前無能為力。具體地說,它難以克服“組合爆炸”和“維數(shù)災難”引起的困難。組合爆炸是指當系統(tǒng)變大的時候,所有可能出現(xiàn)的組合爆炸性增加。例如從國際象棋到圍棋(見圖1),棋盤從8×8變成19×19,其所有可能的組合增加了多個數(shù)量級。零數(shù)據(jù)方法雖然能夠解決國際象棋問題,卻難以解決圍棋問題。

圖1 國際象棋(左)與圍棋(右)棋盤(圖來自互聯(lián)網(wǎng))
維數(shù)災難是指當一個問題的自由度(即維數(shù))增加的時候,計算復雜性呈指數(shù)增加。小數(shù)據(jù)方法可以處理低維問題,但是難以處理高維問題。對于圖像識別、量子化學、動態(tài)規(guī)劃和非線性統(tǒng)計等領域的高維問題,人們只能通過經(jīng)驗、特征工程或者極端的簡化方法處理。量子化學中的哈特里(Hartree)或者哈特里-福克(Hartree-Fock)方法,以及非線性統(tǒng)計中的廣義線性模型(generalized linear models)等都是極端簡化方法的例子。
人工智能經(jīng)過了幾次大起大落,本質(zhì)上都是由于對組合爆炸和維數(shù)災難的困難程度認識不足引發(fā)的。最近幾年,我國仍有團隊提出擺脫大數(shù)據(jù)、以小數(shù)據(jù)方法實現(xiàn)通用人工智能。這個方案的核心問題是它能否克服組合爆炸和維數(shù)災難引起的困難。如果這種思路能夠有效解決圍棋問題,那么它和傳統(tǒng)的零數(shù)據(jù)、小數(shù)據(jù)方法必然有著本質(zhì)的不同。如果不能,那么基于這種思路建立的通用人工智能系統(tǒng)最多也只是一個“弱智”系統(tǒng)。這并不是說零數(shù)據(jù)、小數(shù)據(jù)方法在處理復雜問題時沒有用,而是說僅僅靠這些方法難以走得很遠。我們必須對此有正確的認識。
大數(shù)據(jù)
盡管深度學習受到熱捧之前人們就已經(jīng)在處理和分析大數(shù)據(jù),但是真正讓大數(shù)據(jù)充分發(fā)揮作用的方法是深度學習,其標志性事件是辛頓(Hinton)團隊于2012年贏得ImageNet圖像識別比賽冠軍。辛頓等人設計并訓練了一個神經(jīng)網(wǎng)絡,取名AlexNet。AlexNet有5層卷積網(wǎng)絡、3層全連接網(wǎng)絡,6000多萬個參數(shù)。相比較而言,之前楊立昆(Yann LeCun)訓練的Le-Net只有幾萬個可訓練參數(shù)。
需要強調(diào)的是,辛頓等人在訓練AlexNet的時候用的主要算法,如隨機梯度下降、反向傳播等都是已知的。辛頓團隊的工作就是充分訓練了這樣一個多層神經(jīng)網(wǎng)絡。要做到這一點,就需要高質(zhì)量的數(shù)據(jù)資源和一定的算力資源。這正是ImageNet和GPU發(fā)揮作用的時候。所以辛頓等人的工作既是技術上的成功,更是信念上的堅持帶來的成果。
辛頓等人的工作不僅改變了圖像識別,而且改變了整個人工智能領域,因為基于神經(jīng)網(wǎng)絡的深度學習方法是一個通用方法。神經(jīng)網(wǎng)絡其實就是一類函數(shù),它與多項式這類函數(shù)的不同之處在于它似乎是逼近多變量函數(shù)的有效工具。也就是說,它能夠有效地幫助我們克服維數(shù)災難和組合爆炸引起的困難。事實上,基于深度強化學習的人工智能方法,AlphaGo很快就在圍棋比賽中戰(zhàn)勝了人類最好的選手。神經(jīng)網(wǎng)絡也被用來解決科學領域碰到的多個自由度的問題,如蛋白結構問題、分子動力學勢能函數(shù)問題等,并由此催生出一個嶄新的科研范式:AI for Science。正因為深度學習在多變量函數(shù)逼近這樣一個非常基礎性的問題上帶來了巨大突破,所以它在各種各樣的問題上都給我們帶來了新的可能。
需要強調(diào)的是,盡管很多成功案例都表明深度學習方法是解決高維問題的一個有效工具,但我們對其背后的原因了解得還很不充分。從數(shù)學的角度來說,這是一個非常優(yōu)雅、非常清晰的數(shù)學問題,它將推動高維分析的發(fā)展。關于這方面的工作,請參見我在2022年國際數(shù)學家大會上的報告。
早在20世紀40年代,麥卡洛克(McCulloch)和皮茨(Pitts)就提出了神經(jīng)網(wǎng)絡的概念。50年代,羅森布拉特(Rosenblatt)又提出了感知機的概念。為什么要一直等到2010年左右,人們才開始真正認識到神經(jīng)網(wǎng)絡的巨大威力?我認為其根本原因有兩個:一是訓練好神經(jīng)網(wǎng)絡需要一定的高質(zhì)量數(shù)據(jù)和算力資源,這些條件是一個門檻;二是人們?nèi)狈ι窠?jīng)網(wǎng)絡的正確認識。明斯基(Minsky)和佩珀特(Papert)合著了一本很著名的書,就叫“感知機”(Perceptron)。這本書研究的一個主要問題是:什么樣的邏輯函數(shù)可以用(兩層)感知機精確表示出來?結果他們發(fā)現(xiàn),一些簡單的邏輯函數(shù)都無法用感知機精確表示。這本書的出版給整個神經(jīng)網(wǎng)絡領域的發(fā)展帶來了巨大負面影響。究其原因,明斯基和佩珀特的出發(fā)點是錯誤的:我們應該把神經(jīng)網(wǎng)絡看成是逼近函數(shù)的工具,而不只是看它能夠精確表達什么函數(shù)。而從函數(shù)逼近的角度來說,神經(jīng)網(wǎng)絡不僅能夠逼近一般函數(shù)(universal approximation theorem),而且基于神經(jīng)網(wǎng)絡的逼近和基于其他傳統(tǒng)方法的逼近有著本質(zhì)區(qū)別:傳統(tǒng)逼近方法有維數(shù)災難問題,而神經(jīng)網(wǎng)絡在高維或者多個變量的情形下仍然很有效。
當然,除了維數(shù)災難和組合爆炸之外,還有許多其他問題需要考慮。比如,對文本這類時間序列數(shù)據(jù)來說,能否處理長期記憶(long-term memory)是一個重要問題。有結果表明,循環(huán)神經(jīng)網(wǎng)絡(RNN)有記憶災難問題:即當記憶長度增加時,所需要的神經(jīng)元個數(shù)呈指數(shù)增加。而transformer網(wǎng)絡沒有這個問題。事實上,有理論結果表明,transformer網(wǎng)絡的確能夠有效表達長程但稀疏的記憶依賴關系。這正是大語言模型所需要的。
全數(shù)據(jù)
大數(shù)據(jù)方法考慮的是單個數(shù)據(jù)集,全數(shù)據(jù)方法的思路是把所有數(shù)據(jù)都用起來。比方說,把互聯(lián)網(wǎng)上所有高質(zhì)量文本數(shù)據(jù)都用起來。這里有兩個關鍵問題,一是絕大部分數(shù)據(jù)都是無標注數(shù)據(jù),如何用好這些無標注數(shù)據(jù)?預訓練方法就是為了解決這個問題而誕生的。二是既然我們把所有數(shù)據(jù)都用了,就得把所有可能的下游問題都解決了。也就是說,我們的目標必須是某種形式的通用人工智能系統(tǒng)。這就催生了有監(jiān)督的微調(diào)(SFT)技術。
目前這個思路最成功的實踐出現(xiàn)在文本領域。對文本來說,有兩個最典型的預訓練框架。一是谷歌的BERT,它的出發(fā)點是填空;二是OpenAI的GPT,它的技術路線是預測下一個詞。就目前的發(fā)展情況來看,GPT占了絕對優(yōu)勢。究其原因,是BERT試圖靠上下文內(nèi)容進行語義理解(雙向預測),而GPT只根據(jù)過去預測未來(單向預測),所以GPT既是一個生成模型,又是文本任務的一個通用模型:只要能夠預測下一個詞,我們就可以解決文本領域的所有問題,包括翻譯、對話、寫作等。從智能的角度來說,如果一個機器能夠在不同場景下把預測下一個詞的任務做好,那么它的文本能力就不低于人類。也就是說,它具備了一定的智能的本質(zhì)特性。相比較而言,BERT完成的是一個更加簡單的任務,因為它能夠利用后面的文本內(nèi)容幫助完成填空問題,所以它不需要很強的智能能力。
從理論上來看,大模型帶來的最突出的現(xiàn)象是縮放定律(scaling law)和相應的涌現(xiàn)現(xiàn)象(emergent behavior)。縮放定律源于復雜系統(tǒng)研究,是指當系統(tǒng)規(guī)模變大時,相關指標會按照一定的規(guī)律變化。在大模型領域,它有兩方面的意義。一方面,它讓我們可以從訓練小一點的模型出發(fā),估算出訓練大模型所需要的計算量和數(shù)據(jù)資源;另一方面,它為提升模型的功能提供了一個指導方向。從后者的角度來看,縮放定律起的作用有點像摩爾定律。
應該強調(diào)的是,縮放定律和涌現(xiàn)都是在復雜系統(tǒng)中經(jīng)常能看到的現(xiàn)象。不同的技術框架可以有不同的縮放定律,而優(yōu)化縮放定律應該是我們追求的主要目標之一。當然,我們也可以問:就像摩爾定律一樣,縮放定律終究會有停滯的時候,下一步該如何發(fā)展?
我們還可以把這些不同方法組合在一起,構建更加有效的方法。一個例子是DeepMind推出的AlphaGeometry,它求解國際奧林匹克數(shù)學競賽中平面幾何題目的能力接近了人類最高水平(見圖2)。它的主要想法是把邏輯推理方法和經(jīng)驗方法相結合:定理庫和樹搜索提供具體證明,而機器學習模型提供思路,比如如何加輔助線。毫無疑問,這類想法有著巨大的發(fā)展空間。
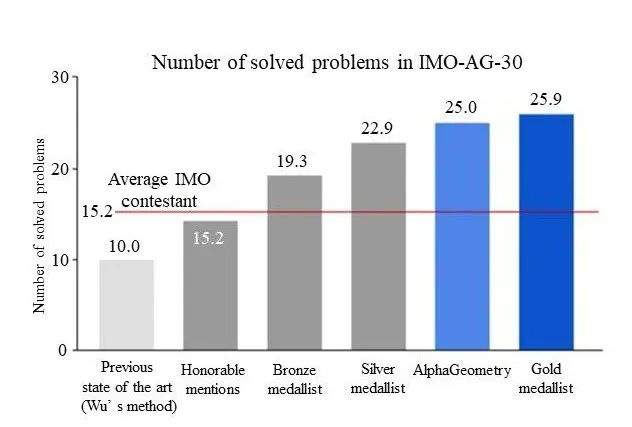
圖2 AlphaGeometry將目前模型的幾何定理證明水平從低于人類水平提高到接近金牌水平
從長遠的角度來看,目前以GPT為代表的技術路徑并不適合我國的國情。首先,在相當長的一段時間里,我國的算力與美國的相比將會有相當大的差距。目前國內(nèi)大模型第一梯隊的算力資源基本上是萬卡規(guī)模(比如英偉達A100),而美國第一梯隊是10萬卡甚至更大規(guī)模。這就意味著在不遠的未來,許多致力于開發(fā)基座模型的團隊可能不得不停下追趕的腳步。其次,GPT存在許多浪費。我們應該尋找更加低能耗、低成本的替代路徑。最近推出的“憶立方”(Memory3)模型就是一種這樣的嘗試。它用內(nèi)置數(shù)據(jù)庫的辦法處理(顯性)知識,避免把知識都存放到模型參數(shù)中,這樣可以大大降低對模型規(guī)模的要求。最后,GPT并不能解決所有問題。在許多方面,比如圖像,我們還需要尋求更加有效的技術方案。
什么才是適合我國國情的人工智能發(fā)展路徑?如何才能保證我國的人工智能長期穩(wěn)定地發(fā)展?要回答這些問題,我們必須在以下兩方面盡快布局。一是建立起一個完整的人工智能底層創(chuàng)新團隊和創(chuàng)新體系,在模型架構、AI系統(tǒng)、數(shù)據(jù)處理工具、高效訓練芯片等方向追求新突破;二是探索人工智能的基本原理,盡管我們與掌握人工智能的基本原理還有很大差距,但是我們已經(jīng)具備了探索這些基本原理的條件。而長期穩(wěn)定發(fā)展的技術路線,必然會在這個探索過程中產(chǎn)生出來。
致謝:在這篇文章的寫作和院士大會報告的準備過程中,我得到了黃鐵軍、楊泓康、袁坤、朱松純等老師的幫助。在此一并表示感謝!
鄂維南
CCF會士。中國科學院院士。北京大學教授。主要研究方向為機器學習、計算數(shù)學、應用數(shù)學及其在化學、材料科學和流體力學中的應用。weinan@math.pku.edu.cn
聲明:本文來自中國計算機學會,稿件和圖片版權均歸原作者所有。所涉觀點不代表東方安全立場,轉載目的在于傳遞更多信息。如有侵權,請聯(lián)系rhliu@skdlabs.com,我們將及時按原作者或權利人的意愿予以更正。
- 周鴻祎領銜!百所高校+企業(yè)組團亮相ISC.AI 2025“紅衣課堂”
- 港科大發(fā)布大模型越獄攻擊評估基準,覆蓋6大類別37種方法
- 引領智能運維!全新FortiAIOps 3.0重新定義IT運營
- MirageFlow:一種針對Tor的新型帶寬膨脹攻擊
- 英偉達約談事件的制度邏輯與趨勢展望
- 國家互聯(lián)網(wǎng)信息辦公室發(fā)布《國家信息化發(fā)展報告(2024年)》
- 火狐中國終止運營:辦公地無人,用戶賬號數(shù)據(jù)面臨清空
- 25年一直未變!網(wǎng)絡安全永恒的“十大法則”
- 關于征集數(shù)據(jù)安全評估標準化應用實踐案例的通知
- ISC.AI 2025主題前瞻:ALL IN AGENT,全面擁抱智能體時代!